


Recent Dashboard Creations
*Note: Specific details on the dashboard have been concealed
The Pipeline Execution Dashboard
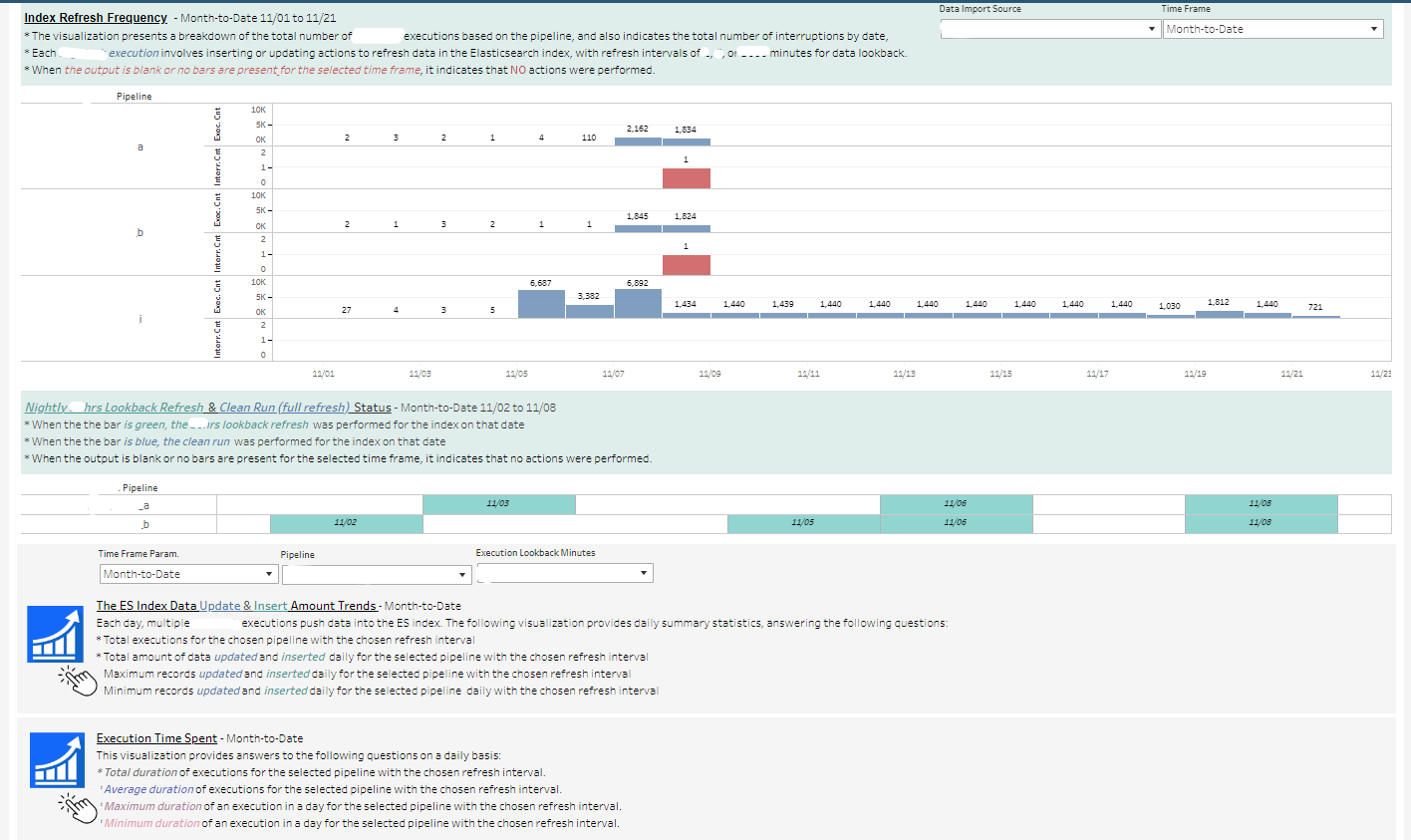
*Note: Specific details on the dashboard have been concealed
The File Processing Dashboard
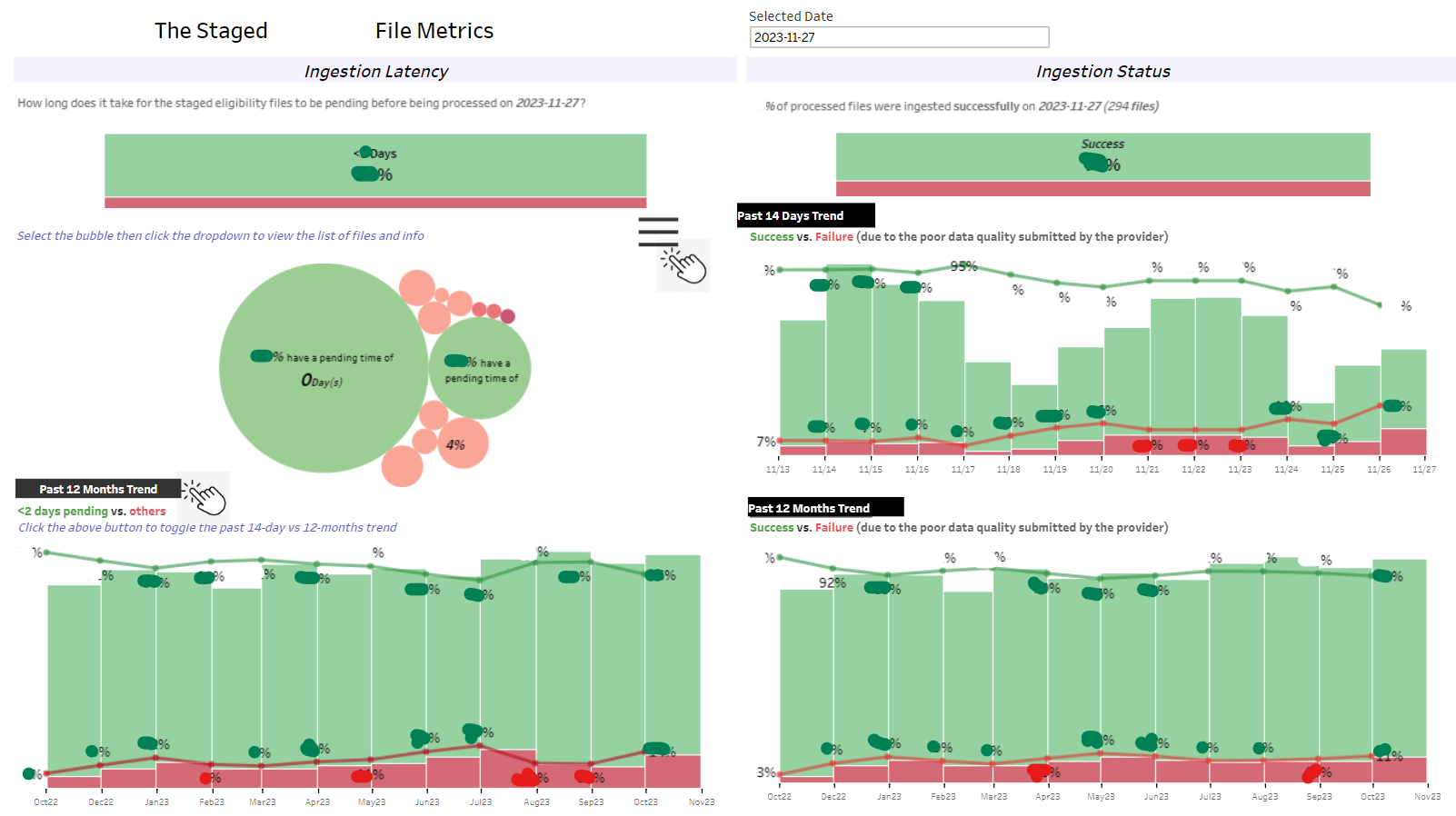
*Note: Specific details on the dashboard have been concealed
The Login Activity Dashboard
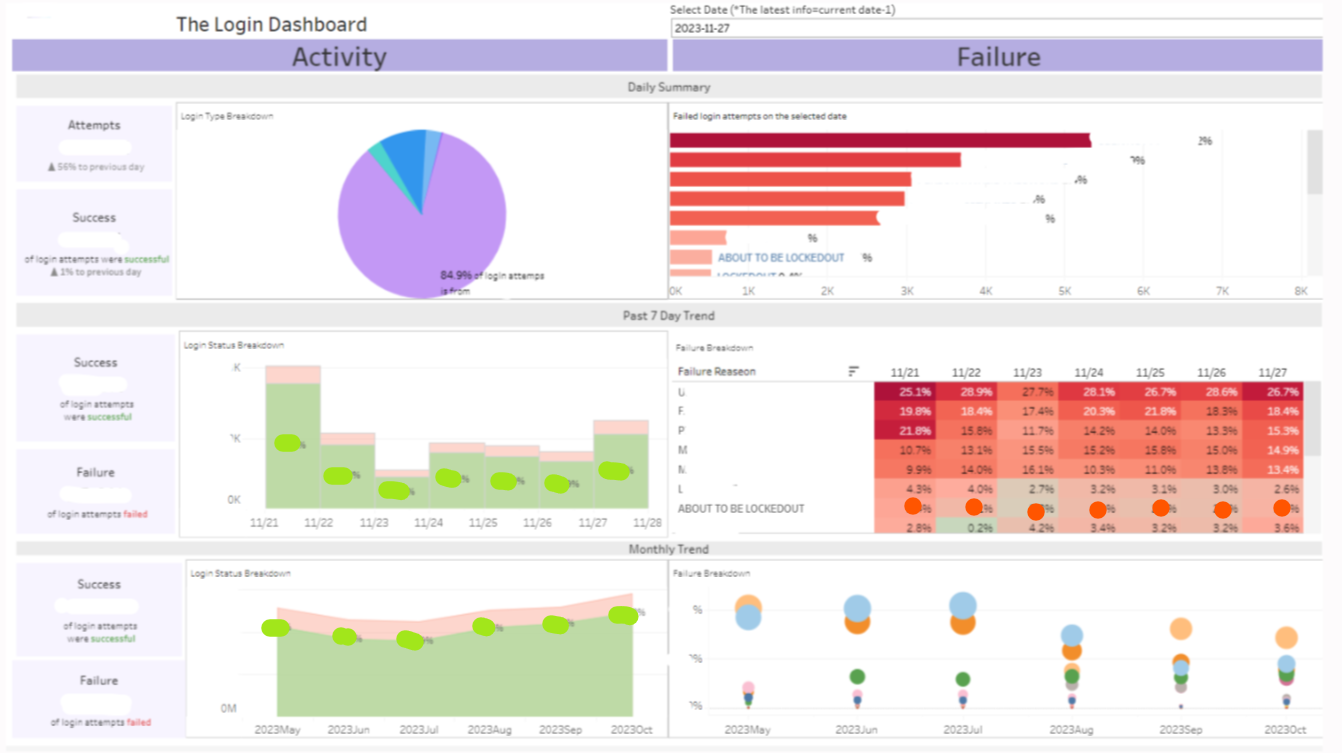
*Note: Specific details on the dashboard have been concealed
The Landing Dashboard
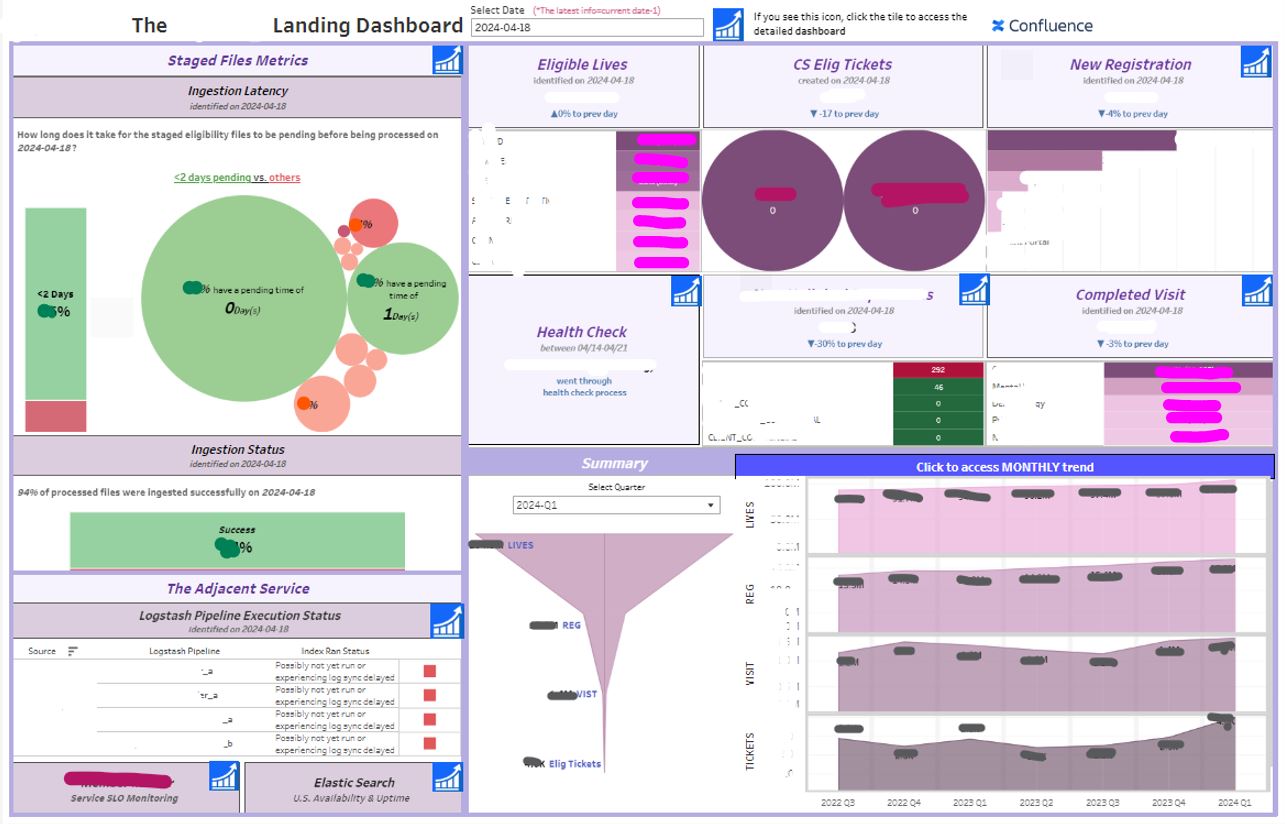
*Note: Specific details on the dashboard have been concealed
The Summery Dashboard

*Note: Specific details on the dashboard have been concealed
The Performance Dashboard

ETL Report Automation Example
-
- 1Develop a scriptfor making API calls to retrieve data from customer support software.
2. The script cleans and logs refined information into a relational table for report generation and trend analysis for a dashboard.
3. Schedule the script on Jenkins pipeline for daily table back-fill to refresh reports and dashboards regularly.
Integrated Recruit Data Fluctuation Monitoring and Categorization Solution
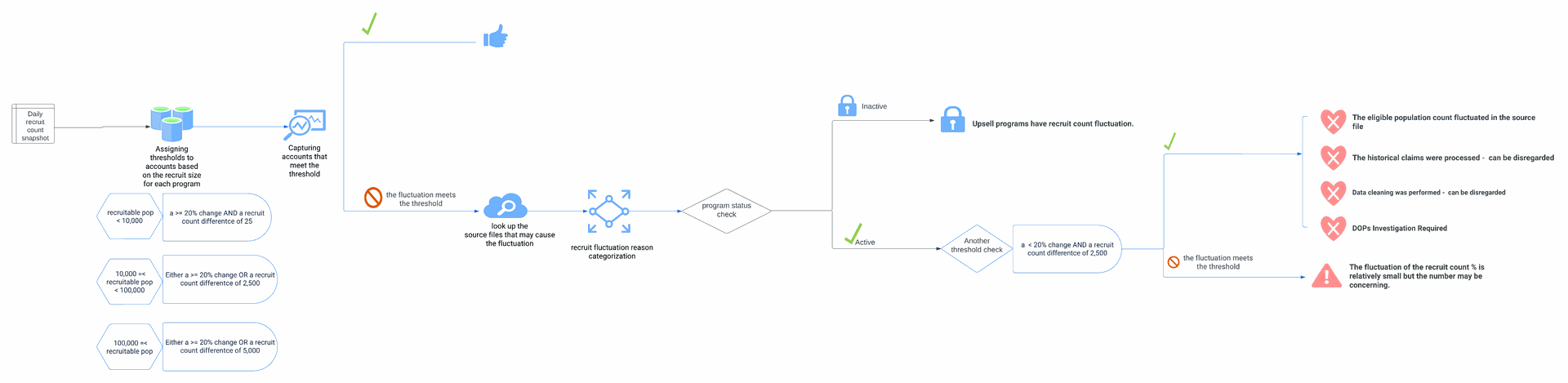
The Goal
Create a process to effectively monitor and notify cross functional teams (the client implementation team, the operation team and the marketing team) about any changes in the number of recruits, which occurred due to the data feeds processed yesterday.
The Result
- Increased Efficiency: By automating the monitoring process
with the Jenkins pipeline, the process runs daily without manual intervention.
This results in significant time savings for the teams involved.
- > 50% of investigation time saved: Categorizing cases into different investigation buckets enables teams to prioritize and focus their efforts efficiently
- Achieved 100% comprehensive case logging for future auditing requirements and maximizing analysis opportunities.
- Standardized Process
Tool & Platform
- Platform: Redshift, Jenkins, Metabase, GitHub, Salesforce
- Language: SQL, batch script
The High Level Steps to Complete the Project
- Conducted the exploratory analysis and observed different scenarios
- Designed the SQL logic (the logic is shown above in the flowchart) to efficiently capture and log accounts that experience fluctuation in recruit counts and categorize cases into different investigation buckets.
- Put the script on the Jenkins pipeline and schedule it to run everyday
- Created a user-friendly Metabase dashboard that can effectively cater to various look back requirements to view previous concerning cases
- Set up an automatic email notification to inform the cross functional teams about the daily concerning cases
- Develop comprehensive documentation and training materials that outline the step-by-step process, as well as troubleshooting techniques, for handling cases that trigger the alarm.
Automated Detection of Client Data Onboarding Delays
The Goal
Establish an efficient process for monitoring the status of client's incoming data, promptly identifying the causes of delays on the pipeline and automate the Jira ticket creation process to track all issues.
Tool & Platform
- Platform: Redshift, Jenkins, S3, GitHub, Jira
- Language: SQL, Python, batch script
The High-Level Steps to Complete the Project
- Use SQL & Python to implement the below logic to identify & categized the delay:
- Compile a list of active files, their corresponding submission cadence and internal file dropped location path.
- Create a rule to identify delays and sync with the manger for approval.
- Categorize the delay reason:
- use the MFT file log to identify whether the delay is due to file submission delay by the data provider
- or it's related to the internal file location configuration issue.
- Log all the alerts in an internal table for the Jira API to print out internal investigation tickets.
2. Put the script on the Jenkins pipeline and schedule it to run every day to print out tickets.
3. Developed comprehensive documentation and training materials that outline the step-by-step process as well as troubleshooting techniques, for handling cases that trigger the alarm.
Enhanced Client's Data Onboarding Workflow with Automated Issue Tracking
The Goal
Establish a process to effectively monitor and detect failures during the pipeline for onboarding clients' external data feeds for the member enrollment process, log these failures, and automate the Jira ticket creation process to track all issues.
Tool & Platform
- Platform: Redshift, Jenkins, S3, GitHub, Jira
- Language: SQL, Python, batch script
The High-Level Steps to Complete the Project
- Collaborate closely with the data engineering team to design a dependable data model and ingestion tool, aimed at storing configured file information and efficiently consuming data. Play an active role in the development process by sharing operational perspectives to drive improvement.
- After the new tool and data model is released, create a script to automatically identify new ingestion failure every week for the ticket creation.
- Put the script on the Jenkins pipeline and schedule it to run every week.
- Create a comprehensive training for the operation team that covers the file ingestion production behavior and the data flow process. Outline a step-by-step troubleshooting process for handling ingestion failure tickets.
Prevalence Analysis
Releasing soon